

Introduction
Zip codes are more than just numbers that help deliver mail. They are also valuable data sources that can be used for various purposes in different industries. For example, it helps businesses target customers, analyze markets, optimize logistics, and improve services.
However, zip codes change constantly, expanding or merging due to population shifts, postal service adjustments, or administrative decisions. They are also not uniform in size, shape, or density, posing challenges for spatial analysis and visualization and not always associated with one city, county, or state, which can create confusion and inconsistency. Moreover, data can come from various sources, such as national postal services or open-source providers, each with its formats, standards, and quality.
💡 For over 15 years, we have created the most comprehensive worldwide zip code database. Our location data is updated weekly, relying on more than 1,500 sources. Browse GeoPostcodes datasets and download a free sample here.
That’s why SQL is a powerful tool for managing postal code data. SQL helps you store, retrieve, update, and analyze postal data efficiently and accurately. It can also help you integrate postcode data with other types of data, such as geographic, demographic, or economic data, to create more comprehensive and insightful datasets.
Learn how these SQL techniques for managing zip code data tie into broader applications like assigning time zones to zip codes in our comprehensive guide on building a zip code to timezone database.
In this article, we will explore how SQL can help you unleash the power of zip code data. We will cover the following topics:
- Understanding postal code databases within SQL frameworks
- SQL techniques for managing data
- Advanced applications

Understanding Zip Code Databases Within SQL Frameworks
SQL database systems are widely used for storing and managing relational data, which means data that is organized in tables with rows and columns. Each row represents a record, and each column represents an attribute of the record. SQL database systems allow us to perform various operations on the data, such as inserting, updating, deleting, or selecting records based on certain criteria.
Essential Fields
The essential fields in a zip code database are:
- Zip Code: The digit code that identifies a postal delivery area. This is the primary key of the table, which means it uniquely identifies each record and cannot be null or duplicated.
- Country: Contains the country’s ISO code to make a distinction in worldwide datasets.
- City: The name of the city or town corresponding to the postal code. This text field can be different lengths depending on the database system. If a postal code has several cities, we can add a primary key to refer to.
- Region: This is also a text field that corresponds the region to the zip code. Depending on local administrative divisions, your database can contain several region fields: Region 1, Region 2, Region 3,…
- Latitude: The geographic coordinate that specifies the north-south position of the zip code.
- Longitude: The geographic coordinate that specifies the east-west position of the zip code.
Depending on the application, a database can have additional fields, such as county, population, income, or area code. However, these fields are not essential for identifying and locating a postcode.
Curious to see an example? Check our zip code database samples and download them for free.
Choosing the Right Database System
There are many SQL databases available, such as MySQL, PostgreSQL, Oracle, SQL Server, SQLite, and others. Each of them has its advantages and disadvantages, and the choice of the right database system depends on several factors, such as:
- Data size and complexity: Some database systems can handle larger and more complex data than others and offer more features and functions to manipulate the data. PostgreSQL and Oracle are known for their scalability and performance, while SQLite is more suitable for smaller and simpler data.
- Data compatibility and interoperability: Some database systems work better with other software or platforms than others and offer more options to import and export data. MySQL database and SQL Server are compatible with many web development frameworks and tools, while SQLite can be embedded into applications and run on various devices.
- Data cost and availability: Some database systems are free and open source, while others are proprietary and require a license fee. MySQL and PostgreSQL are free and open source, while Oracle and SQL Server are commercial and require a license fee.

Benefits of Normalization in Database Design
Normalization is a process of organizing data in a database to reduce data redundancy and improve data integrity. It involves applying a series of rules or normal forms to the data, which splits a large table into smaller and more manageable tables and establishes relationships between them.
Normalization has many benefits for database design, especially for postal code data, such as:
- Eliminate data duplication and inconsistency: Normalization saves storage space and prevents errors and conflicts. For example, if a postcode has more than one city or state associated with it, normalization separates the zip code and the city/state into different tables and links them with a foreign key.
- Simplify data manipulation and querying: Normalization improves performance and efficiency. Let’s say a postal code has additional fields, such as population or income, normalization groups them into a separate table and joins them with the zip code table when needed. This can make the queries faster and easier to write.
- Enhance data integrity and security: Normalization ensures data accuracy and quality. For example, if a zip code or a city/state changes, normalization makes the update easier and consistent and prevents data loss or corruption. Normalization can also enforce constraints and validations on the data, such as primary and foreign keys, which can prevent invalid or unauthorized data entry.
Normalization is an important and useful technique for database design, but it is not always necessary or optimal. Sometimes, normalization can result in too many tables and joins, reducing performance and readability. It can also remove useful information or relationships, affecting the database’s functionality and usability. Therefore, the degree and method of normalization should be carefully considered and balanced according to the user’s specific needs and goals.
SQL Techniques for Managing Zip Code Data
Now we can explore some SQL techniques for managing zip code data efficiently. In this section, we will cover the following topics:
- Writing effective SQL queries
- Maintaining data integrity
- Performance tuning and indexing
Writing Effective SQL Queries
SQL queries are the primary way to interact with data stored in a database. SQL queries allow us to retrieve, sort, filter, and manipulate data according to our needs and preferences.
Here are some examples of SQL queries for US zip codes:
- To select all the fields from a zip code table, we can use the following query:
SELECT
*
FROM
zip_code
;SELECT * FROM zip_code ;
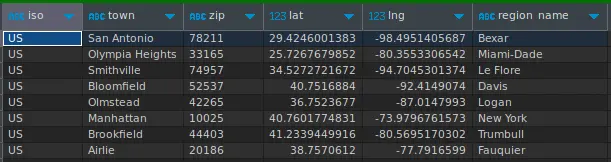
- To select only the zip code, city, and state fields from a zip code table, use the following query:
SELECT
zip_code, city, state
FROM
zip_code
;
SELECT zip_code, city, state FROM zip_code ;
- To select only the zip codes that start with 9 from a zip code table, use the following query:
SELECT
zip_code
FROM zip_code
WHERE
zip_code
LIKE
'9%'
;SELECT zip_code FROM zip_code WHERE zip_code LIKE '9%' ;
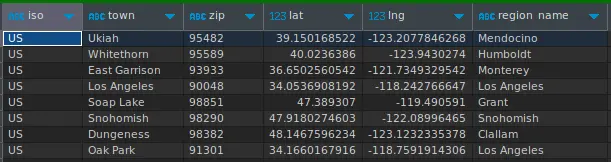
- To select only the zip codes that belong to California, use the following query:
SELECT
zip_code
FROM
zip_code
WHERE
state = 'CA'
;SELECT zip_code FROM zip_code WHERE state = 'CA' ;
- To select only the zip codes that have a latitude between 30 and 40 degrees, use the following query:
SELECT
zip_code
FROM
zip_code
WHERE latitude
BETWEEN 30
AND 40
;SELECT zip_code FROM zip_code WHERE latitude BETWEEN 30 AND 40 ;
- To select the zip codes and their corresponding cities and states and sort them by zip code in ascending order from a zip code table, use the following query:
SELECT zip_code, city, state
FROM zip_code
ORDER BY
zip_code
ASC
;SELECT zip_code, city, state FROM zip_code ORDER BY zip_code ASC ;
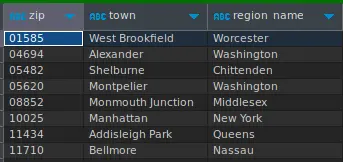
- To select the zip codes and their corresponding cities and states and filter them by a list of states from a zip code table, we can use the following query:
SELECT
zip_code, city, state
FROM zip_code
ORDER BY
zip_code
ASC
;SELECT zip_code, city, state FROM zip_code ORDER BY zip_code ASC ;
- To select the zip codes and their corresponding cities and states and filter them by a range of zip codes from a zip code table, we can use the following query:
SELECT
zip_code, city, state
FROM zip_code
WHERE state
IN ('CA', 'NY', 'TX')
;SELECT
zip_code, city, state
FROM zip_code
WHERE state
IN ('CA', 'NY', 'TX')
;- To select the zip codes and their corresponding cities and states and filter them by a range of zip codes from a zip code table, we can use the following query:
SELECT zip_code, city, state
FROM zip_code
WHERE zip_code
BETWEEN '90000'
AND '99999'
;SELECT zip_code, city, state FROM zip_code WHERE zip_code BETWEEN '90000' AND '99999' ;
These are just some examples of SQL queries for postal codes. Many more possibilities and variations can be used to suit different scenarios and requirements. The key to writing effective SQL queries is to use the appropriate syntax, operators, functions, and clauses to achieve the correct desired outcome. You can refer to this documentation for more information and examples of SQL queries.
Maintaining Data Integrity
Data integrity is the quality and consistency of data in a database. Various factors, such as human errors, system failures, malicious attacks, or data corruption, can compromise data integrity.
To maintain data integrity, SQL provides various mechanisms and features, such as:
- Constraints: Rules that define the valid values and formats for the data in a table. Constraints can be applied at the column level or the table level and can be enforced by the database system or the application. Constraints can help prevent invalid or inconsistent data entry and ensure the data meets the business logic and requirements. For example, we can use a primary key constraint to ensure each zip code is unique and not null in a zip code table. We can also use a foreign key constraint to ensure that the postal code in a customer table references a valid postal code in a table. We can also use a check constraint to ensure that the latitude and longitude values in a zip code table are within the valid ranges. For more information and examples of constraints, you can refer to this article.
- Triggers: Triggers are actions that are executed automatically when a certain event occurs in a database. They can be used to perform additional tasks or validations when data is inserted, updated, or deleted in a table. It helps maintain data integrity by enforcing business rules, auditing data changes, or synchronizing data across tables. For example, a trigger can update the population field in a zip code table whenever a new customer is added or removed from a customer table. Also, a trigger is used to log the data changes from a zip code table to a history table for auditing purposes. Use a trigger to update the city and state fields in a customer table whenever the zip code field is changed.
- Transaction controls: Transaction controls are commands that control the execution and completion of a set of SQL statements that form a logical unit of work. Transaction controls ensure data is consistent and accurate before and after the transaction. Transaction controls can also help prevent data loss or corruption in case of system failures or errors. Transaction controls include the following commands:
- BEGIN TRANSACTION: This command marks the start of a transaction.
- COMMIT TRANSACTION: This command commits the transaction’s changes to the database.
- ROLLBACK TRANSACTION: This command rolls back the changes made by the transaction and restores the database to its previous state.
- SAVE TRANSACTION: This command saves a point in the transaction that can be rolled back to later.
- BEGIN TRANSACTION: This command marks the start of a transaction.
For example, we can use transaction controls to ensure that the data in a zip code table and a customer table are updated consistently when a customer changes their address. We can also use transaction controls to ensure that the data in a zip code table and a history table are updated together when a zip code is modified.
Advanced Applications of Zip Code Data in SQL
Zip code data is useful not only for identifying post offices, and locating postal delivery areas but also for various other purposes that require more complex and sophisticated SQL techniques.
In this section, we will explore some of the advanced applications of zip code data in SQL.
Integrating Zip Code Data with GIS Systems
GIS (Geographic Information System) is a system that captures, stores, analyzes, and displays geographic data. GIS can help visualize and understand spatial patterns and relationships, such as distances, directions, areas, and shapes.
GIS can also help perform spatial operations and calculations, such as finding the nearest or farthest locations, measuring the length or area of a feature, or determining the intersection or union of two features.
SQL can be used to integrate zip code data with GIS systems, as both use relational databases to store and manipulate data. SQL can also use the geography data type, representing data in a round-earth coordinate system. The geography data type provides many built-in methods and functions that can help perform GIS-related tasks, such as geocoding, geospatial analysis, or spatial indexing.
For example, SQL can use the geography data type to create a GIS service that allows users to search for nearby amenities based on their zip code. The service can use the following steps:
- Convert the user’s zip code input into a geography point instance using the STPointFromText method.
- Join the zip code table with the amenity table based on the zip code column, and select the amenity name and location (latitude and longitude) fields.
- Convert the amenity location fields into geography point instances using the STPointFromText method.
- Calculate the distance between two zip codes: the user’s zip code point and the amenity points using the STDistance method.
- Filter the results by a distance threshold, and sort them by distance in ascending order.
- Return the amenity name and distance fields to the user.
Customer Profiling
Profile customers based on their zip codes to understand their preferences, behaviors, and purchasing patterns. Customer profiling involves creating detailed descriptions of customers based on various attributes such as demographics, purchasing behavior, preferences, and geographic location (such as zip codes).
Segment customers based on their zip codes to understand regional differences in purchasing behavior.
-- Segment customers by zip code regions
SELECT zip_code_region, COUNT(*) AS customer_count
FROM (
SELECT
CASE
WHEN zip_code LIKE '1%' THEN 'Region 1'
WHEN zip_code LIKE '2%' THEN 'Region 2'
-- Define more regions based on zip code patterns
ELSE 'Other'
END AS zip_code_region
FROM customers
) AS customer_regions
GROUP BY zip_code_region;-- Segment customers by zip code regions SELECT zip_code_region, COUNT(*) AS customer_count FROM ( SELECT CASE WHEN zip_code LIKE '1%' THEN 'Region 1' WHEN zip_code LIKE '2%' THEN 'Region 2' -- Define more regions based on zip code patterns ELSE 'Other' END AS zip_code_region FROM customers ) AS customer_regions GROUP BY zip_code_region;
Dynamic Pricing
Automate dynamic pricing strategies based on zip code data, such as adjusting prices based on regional demand or cost factors.
-- Update product prices based on zip code regions
UPDATE products
SET price = price * 1.1 -- Increase price by 10% for specific regions
WHERE zip_code IN ('ZIP_CODE_1', 'ZIP_CODES_2');-- Update product prices based on zip code regions
UPDATE products
SET price = price * 1.1 -- Increase price by 10% for specific regions
WHERE zip_code IN ('ZIP_CODE_1', 'ZIP_CODES_2');Conclusion
The zip code database SQL question shows research effort. In this article, we have learned how SQL can help us unleash the power of zip code data. We have covered the following topics:
- Understanding zip code databases within SQL frameworks
- SQL techniques for managing zip code data
- Advanced applications of zip code data in SQL
Zip code data is a valuable source of information that can be used for various purposes in different industries. SQL is a powerful tool for storing, retrieving, updating, and analyzing zip code data accurately.
We hope this article has inspired you to explore and experiment with zip code data and SQL. We also invite you to share your feedback and suggestions and provide details with us. After delving into the intricacies of SQL queries within a zip code database, you might seek a comprehensive and reliable resource to streamline your location data management. Geopostcodes maintains the most accurate and complete worldwide database of postal codes and address data. See for yourself and download a free sample.
FAQ
What is SQL zip code?
SQL zip code typically refers to storing zip code data in an SQL (Structured Query Language) database. It’s a way of organizing and managing zip code information using SQL commands to query, update, and manipulate the data.
What is the database type for zip code?
It depends on the specific requirements and preferences of the application, but commonly used types include relational databases like MySQL, PostgreSQL, or SQL Server, as well as NoSQL databases like MongoDB for more flexible data structures.
What data type is a zip code?
Storing a zip code as a numeric value is not the answer. In SQL, a zip code should typically be stored as a VARCHAR data type rather than an integer to preserve leading zeros and accommodate alphanumeric formats. This allows for accurate representation of zip codes, especially in regions where they contain letters or special characters.
Storing zip codes as VARCHAR ensures compatibility with various international postal systems and prevents data loss or truncation. Additionally, VARCHAR provides flexibility for future changes in zip code formats or expansions.

